Seeing how functions change the way one looks at compute workloads in terms of products makes me wonder how one/companies can look at their analytics workloads and try to see if it was possible to change the costing model in that direction.
Previously, 1-2 years ago, if one told me that they needed to run some automation scripts written in python or R languages, I would probably stretch my fingers and immediately begin work deploying a Linux compute service. I would manually install all the dependencies needed and proceed to give the required users access to the servers before continuing on my way. This meant that the server would continue to operate continuously. They aren’t going to keep shutting it down and then re-asking the engineers to recreate the servers over and over again; it’s going to cost more if done that way.
Fortunately, times have changed quite a bit since then. Other automation tools came along (e.g. Ansible, Packer, Terraform), then containers came (e.g. Docker) and now, the big movement from the industry, functions as a services (FAAS).
Let’s say if we chose to develop our analytical workload onto FAAS by a cloud provider. Just imagine writing a function and then throwing it to a provider and letting the provider figure out how to run that service. One no longer has to think of how to ensure that the machine provisioned had to be able to take on all the analytical load during that time and even ensuring that the cost of provisioning the machine being kept as low as we possibly can.
However, rather than keep going on how awesome the FAAS model for running workloads is, let’s have a sample application workload that we can work with. Over here, it is mainly demonstrated with Google Cloud Functions, but I would imagine it would work well with
Scenario #
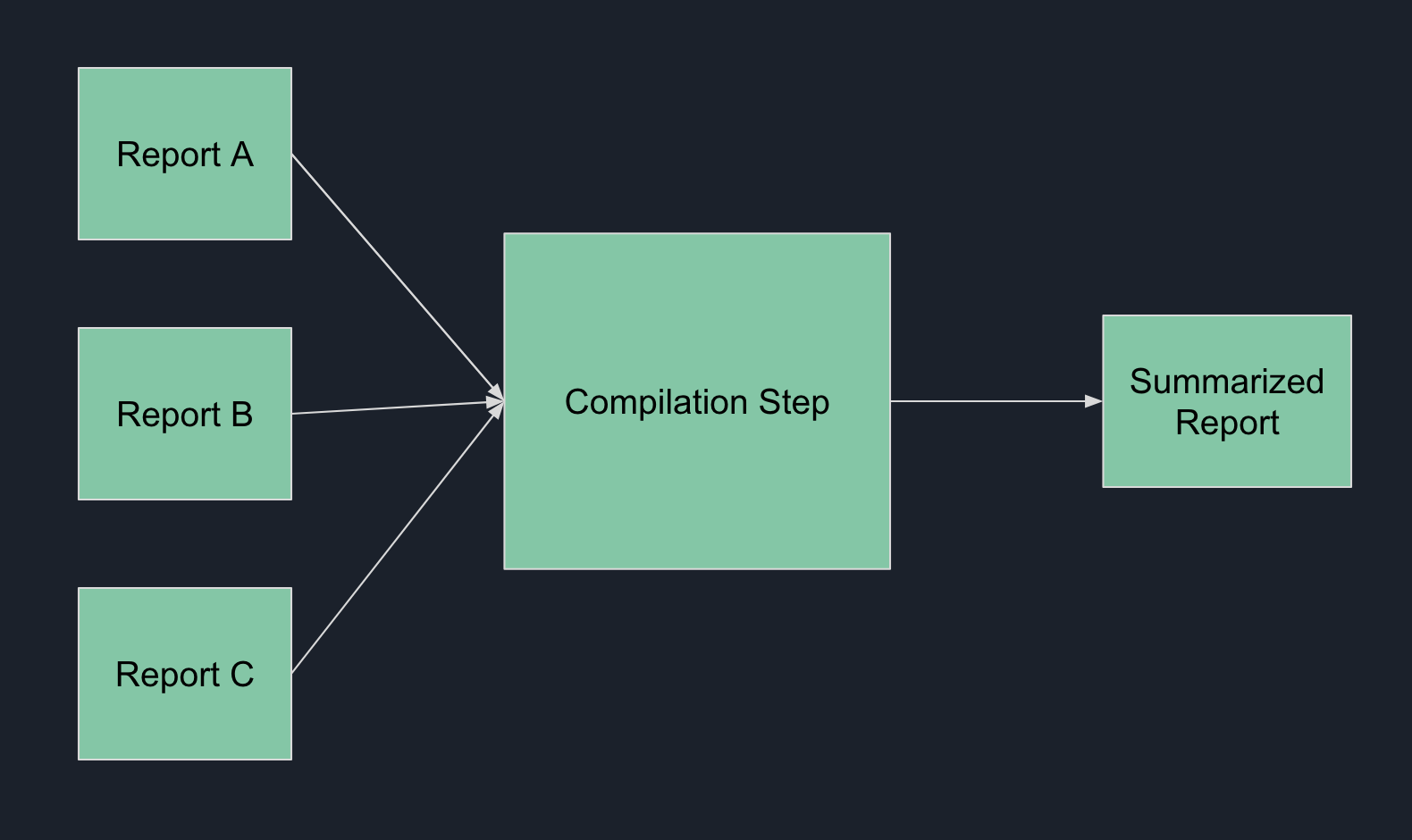
Let’s imagine that we have the following scenario. We have a main analytics department that needs to compile a report from 3 other departments. Let’s have this main analytics department be nicknamed main. For the rest of the reports, they would be produced by team A, team B and team C respectively. (E.g. team A would produce the report A). The usual workflow for this is the following:
- main requests for the subreports to be submitted
- team A sends in report A
- team B sends in report B
- team C sends in report C
- main team compiles the report and submit it to the business team with their insights which can empower the whole business to make data driven decisions
Unfortunately, the above is usually just the ideal case. More likely than not is that the below would happen
- main requests for the subreports to be submitted
- team A sends in report A
- team B sends in report B
- report A has many errors; needed to be corrected by team A and resubmitted
- team C A reminder email needs to be sent
- team B An error was realized by an analyst on the main team (summing some of the columns meant that the data wasn’t filtered properly etc) - report needs to be resubmitted once more
- etc….
The process, if done well could take over a single day but due to many potentials issues that can come up, it becomes highly unlikely that the ideal scenario could take place. Due to the back of forth for report requests, a “simple” report that was expected to be completed and done in 2-3 days could end up requiring a whole week or longer before it gets submitted. It gets kind of weird and funny when you imagine that the weekly report that a business team would receiving was over 1 week overdue, making it harder to correlate actions to the results reported.
Humans are prone to errors, an error free month in the current month doesn’t mean an error free reports moving forward. Other factors can come to play where the main team could have requested the data too late, and the respective team doesn’t have time to compile the report that they are supposed to deliver etc.
How can we try fixing this? #
Part of the reason why the report can take longer is that humans are previously needed to check the report. And sometimes, even if there is a script, a human worker still needs to step in to run the report. This means that the teams that does the subreports (in our case, report A, B and C) would have some lag before they know if their reports are useful and correct to be used for analysis in the main report.
Based on the above, it would be nice if the guys working on the sub reports would get instant feedback so that they immediately continue working on it without waiting a day or two for feedback on what went wrong for their report.
And here’s where part 1 of the solution can kind of come in; Google Cloud Functions can be triggered when a report is dropped into a storage bucket. So a team that was working on a report could upload the report to a storage bucket and that could immediately trigger an function that could check the report being submitted.
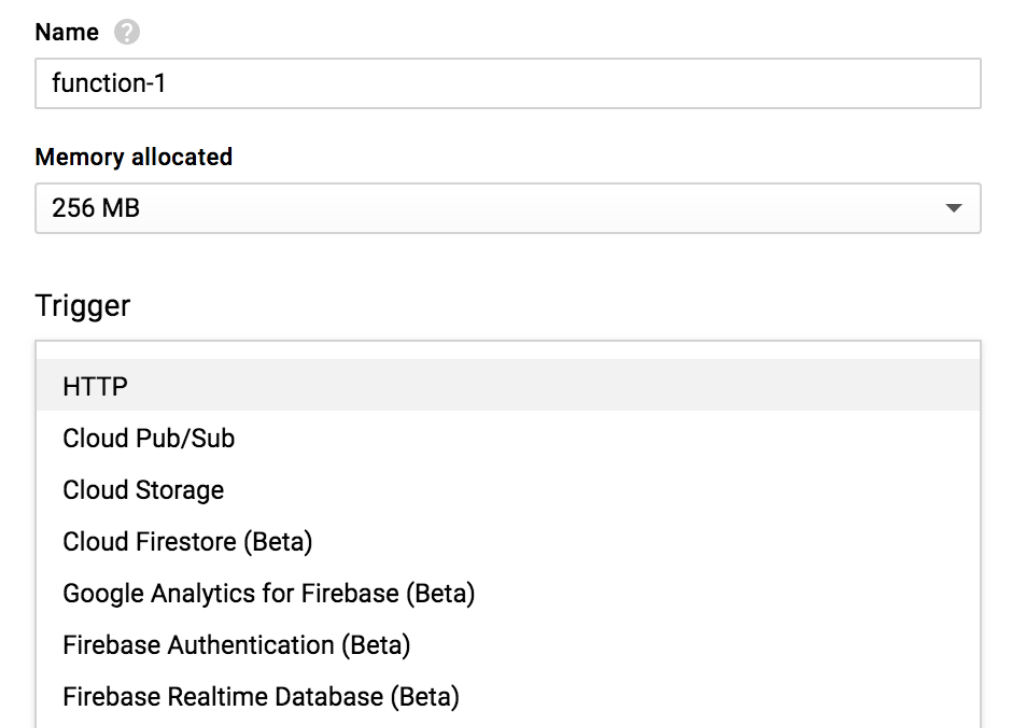
You can view the following possible options on the various triggers one could use while creating the cloud function:
Now that we have our trigger setup, we can then write our function which would run in order to check our data.
Let’s say that this was the main logic that we would want to run on each dataset.
- We would want to ensure that all the columns that was specified here is there and available on the dataset
- We would want to check that there is at least a row of data available in each dataset
Over here, we are assuming that the data has been read via the panda’s library as a python dataframe, which would allow us to manipulate it accordingly.
import pandas as pd
def run_check(data):
assert isinstance(
data, pd.DataFrame), "Expected data to be a pandas dataframe"
errors = []
# Number of rows is more than 0
data_shape = data.shape
if data_shape[0] <= 0:
errors.append("Empty dataset")
# Column check
expected_keys = ["id", "data", "source", "target", "state"]
columns = data.columns
for key in expected_keys:
if key not in columns:
errors.append("{} column is missing".format(key))
return errorsTo tie the above functionality together, we would also need to note that the Google Cloud Storage bucket does not provide the function the actual file for us to check. It would only provide the metadata of the file that was being dropped into the bucket. Some examples of the data available would be:
- Name of the file being dropped
- “Folder” of the file being dropped in bucket
- Timestamp of the file being dropped
- Information on whether the file has any expiry dates before it gets automatically deleted etc
Further information on these can be found here: https://cloud.google.com/functions/docs/writing/background https://cloud.google.com/storage/docs/json_api/v1/objects
We would need to do the following in order to run our checks end to end (this includes informating the team responsible for the report):
- Pull in our configuration/secret files from someone. A possible place to store our config keys is in a bucket. However, one can probably store it in more secure places; it justs needs to be added into the function
- Downloading the file from bucket into the Cloud Function which it can process further and run its checks
- Send error/successful logs to the communication channel. In this example, it is done via Slack.
def main(data, context):
"""Background Cloud Function to be triggered by Cloud Storage.
Args:
data (dict): The dictionary with data specific to this type of event.
context (google.cloud.functions.Context): The Cloud Functions
event metadata.
"""
bucket_id = data['bucket']
file_name = data['name']
assert isinstance(bucket_id, str), "Bucket id provided is not a string"
assert isinstance(file_name, str), "Filename provided is not a string"
# Retrieve configuration files
client = storage.Client()
bucket = client.get_bucket('gcf-test-analytics-demo1')
blob = bucket.get_blob('config/config.json')
keys = blob.download_as_string()
keys_json = json.loads(keys)
# Retrieve slack channel id
slack_token = keys_json['slack_token']
slack_channel_name = keys_json['slack_channel_name']
channel_id = slack.get_channel_list(slack_token, slack_channel_name)
slack.send_text_to_channel(
slack_token, channel_id, "Received csv file. Will begin checking")
# Download file and process it
data_blob = bucket.get_blob(file_name)
try:
data_blob.download_to_filename("/tmp/{}".format(file_name))
data = pd.read_csv("/tmp/{}".format(file_name))
except Exception as e:
logging.error(e)
err_list = analytics_check.run_check(data)
if len(err_list) > 0:
error_test = ""
for item in err_list:
error_text = "{}\n{}".format(error_text, item)
slack.send_text_to_channel(
slack_token, channel_id, error_text)
else:
slack.send_text_to_channel(slack_token, channel_id, "All good")The full codebase for this can be found here: https://github.com/hairizuanbinnoorazman/gcf-analytics/tree/demo1
Concluding part 1 #
The above code should handle the cases where sub reports being submitted are being immediately checked and the feedbacks for those said checks are being returned to the team involved. E.g. Now the team that sent the report do not need to “recheck” their work. If the functional check say it’s ok, then it should be probably ok to move on with their life without worrying if the “main” analytics team would come back to them, requesting for even more information and changes on the report they sent in.
And with that, we’re done with part 1 of our long solution. There is another part which talks about the secondary portion which is the compilation of our subreport.